
Topics covered in this blog:
- Introduction to Spark
- Driver program in Spark
- Cluster Manager in Spark
- Worker Node in Spark
Introduction to Spark:
Spark is a favorite tool in data engineering and machine learning. It is used for big data processing and transformation. It is built on Scala and internally uses Java JVM(Java Virtual Machine) to execute code. We can use Spark with Python, R, Scala, and Java. In this blog, I will try to explain Spark's architecture. I will also explain each component used inside Spark. You can read more about it here
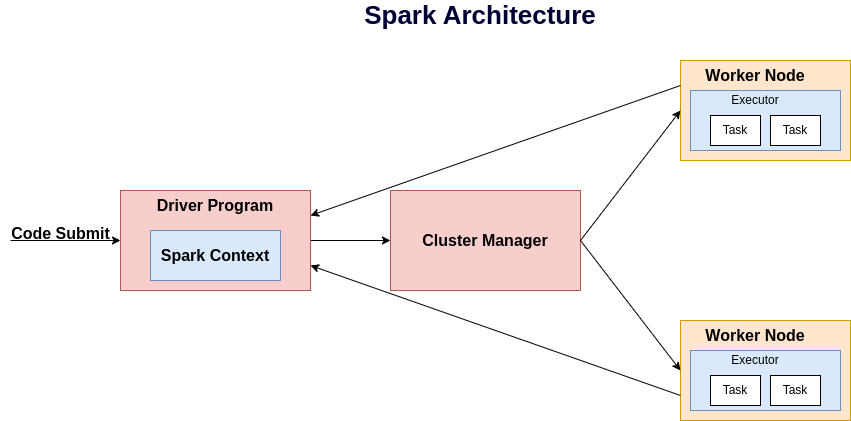
So, internally, Spark uses the following components in its architecture:
- Driver Program / Main Program
- Cluster Manager
- Worker Node & Executor Program
Driver Program in Spark:
The Driver program is the main program of Spark. When we submit our code, the driver program executes and initiates a Spark context. Spark context is the entry point of Spark. (In the latest version of Spark Spark session is the entry point which keeps the Spark context internally). Spark context is the heart of Spark.
Spark is responsible for the following tasks- It is the bridge between the driver and the cluster manager.
- Spark context also keeps the basic configuration of the application, like RAM, CPU, etc.
- Spark Context is responsible for the resource manager and also manages tasks related dependencies, parallelism between tasks.
- Spark context is responsible for a distributed environment with RDD and DataFrame.
- Logging and error handling is also handled by the Spark context.
Cluster Manager in Spark:
The Cluster manager is responsible for allocating and scheduling resources across multiple applications. The cluster manager manages only resources, not tasks.
There are multiple types of cluster managers available in Spark:
- Standalone mode: It is built into the cluster manager and uses the local system for development purposes.
- Yarn: It is part of the Hadoop ecosystem, where we read data from HDFS.
- Kubernetes
- Mesos
Worker Node & Executor Program:
The Worker node is the machine that keeps actual business data, and program execution takes place here. To execute code in a worker node, the executor program executes the code. Its main responsibility is to execute the code. In a single node, there is the possibility of having more than one executor. Basically, when we submit our code at that time we have to decide the number of executors in each node. This information is kept by the Spark context. The executor executes the code, and the result may be stored in cache/storage or sent back to the driver program to print the final result.
Interview Questions
- Explain Spark Architecture.
- What is Driver Program in Spark?
- Explain Cluster Manager.
- Explain Executors in Spark.
