
Spark is a big data processing engine that can be used in multiple languages, such as Python, Scala, Java, and R. It handles big data and helps in machine learning and data science. Spark runs on a single machine( node) and a cluster as well. Spark follows a distributed architecture where data is kept in one or more nodes(machines), and Spark provides resources and code and executes code in all necessary nodes, and consolidates their result and sends them back to the master node.
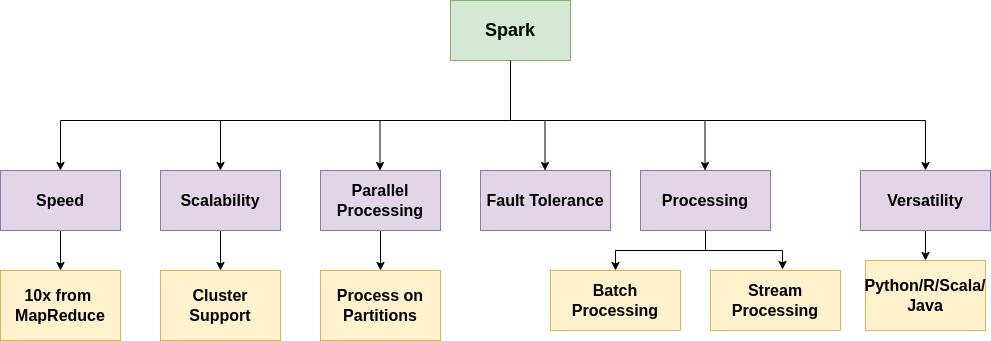
Features of Spark:
- Speed - Spark’s best feature is its in-memory caching, which makes it 10 times faster than MapReduce(Hadoop). The main question is, how is Spark so fast? The answer is Spark's in-memory caching technique. Basically, Spark stores intermediate results in memory and uses these results whenever required. This logic reduces the I/O operation from the hard disk and makes it so fast.
- Scalability - Spark can work with a large cluster without/minimal user intervention. Spark can do parallel processing with a single machine or a large cluster.
- Parallel Processing - Parallel processing is a most powerful feature of Spark. Data is split into small chunks and stored in partitions. Spark dispatches tasks to these partitions based on the requirement and processes them in parallel.
- Fault Tolerance - Spark uses RDD (Resilient Distributed Dataset), which is fault-tolerant. I will explain this concept separately.
- Batch & Streaming Processing -
- Batch Processing- Batch processing is used to handle the large volume of data in small chunks with the help of tasks. These tasks require minimal user interaction. Generally, we use batch processing for ETL(Extract, Transform, and Load). Batch processing is generally used with historical data to find insightful information to make big decisions in business.
- Stream Processing- Spark not only handles batch data but also handles real-time streamed data. Spark ingests real-time data from multiple sources and makes small batches of it and then processes and analyzes that data, and lastly either stores it somewhere or populates in dashboard. So, Spark Streaming is nothing but micro-batch processing or near real-time processing of structured data. Generally, organizations use Spark Streaming for IOT, analyze error logs, and so on.
- Versatility: Spark is a very versatile and useful tool. It provides api for other languages. So, users can use it’s own favorite language(Python/R/Scala/Java) and use Spark’s distributed architecture.
