
RDD is immutable, it can be created by either reading a file or the parallelize method. Apart from these two methods, we can create RDD by applying some transformation on an existing RDD, which will give us a new RDD.
RDD1 + some transformation = RDD2
Whenever we apply these transformations, it will not give results immediately because Spark follows lazy evaluation; it requires an action method to start the process. So, Spark stores the process and waits for action. Spark stores this process in a graphical manner, which is known as a lineage graph. This graph holds the parent RDD, transformation, and result RDD in vertices and an edge, where the vertices are for the RDD and the edges are for the transformation.
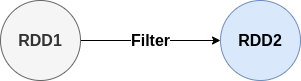
Rather than keeping the actual value, it keeps a logical plan. So, in the future, whenever we lose our RDD, we use this graph to recalculate the lost RDD from the point where the crash happened. This graph lineage is known as the RDD lineage.
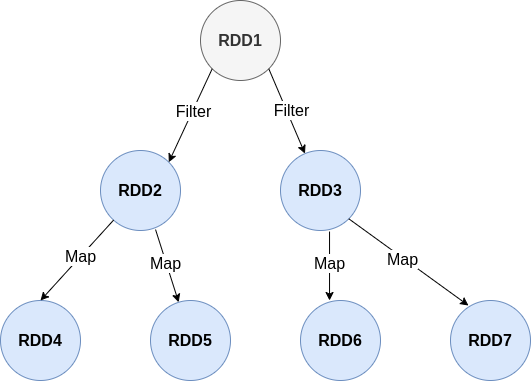
Ex.
RDD1 = sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
RDD2 = RDD1.filter(x => x % 2 == 0)
RDD3 = RDD1.filter(x => x % 3== 0)
RDD4 = RDD2.map(lambda x: x*x)
RDD5 = RDD2.map(lambda x: x*x*x)
RDD6 = RDD3.map(lambda x: x*x)
RDD7 = RDD3.map(lambda x: x*x*x)
Answer in Interview
RDD Lineage is a graphical representation of the operation applied on RDD to create the new RDD. It is based on the vertices, which represent the RDD, and the edges, which represent the transformation. RDD Lineage is useful to recalculate the intermediate result.
Expected Questions
- What is the RDD Lineage?
- How does Spark recalculate the lost intermediate calculation?
- Explain how Spark creates logical plans.
